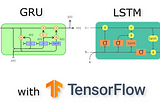
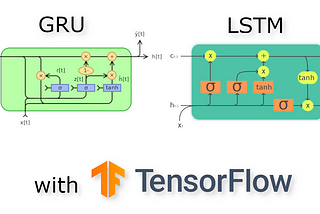
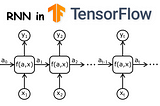
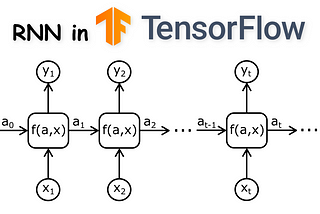
Dorian LazarinNabla SquaredCharacter-level Deep Language Model with GRU/LSTM units using TensorFlowIn this article, I’m going to show how to implement GRU and LSTM units and how to build deeper RNNs using TensorFlow. I will start by…·13 min read·Jul 20, 2021----
Dorian LazarinNabla SquaredCreating a simple RNN from scratch with TensorFlowAnd using it to build a language model for news headlines·12 min read·Jul 1, 2021----
Dorian LazarinNabla SquaredHow to use C code in Python… and should we do this?·9 min read·May 31, 2021----
Dorian LazarinNabla SquaredHow to prettify your code in a Jupyter NotebookUse the Code Prettify Jupyter Extension·3 min read·May 3, 2021----
Dorian LazarinNabla SquaredWhat are GANs?A brief introduction to Generative Adversarial Networks·7 min read·Dec 4, 2020----
Dorian LazarinNabla SquaredHow to change the autosave interval in Jupyter NotebooksYou can use this Jupyter extension·3 min read·Nov 30, 2020--1--1
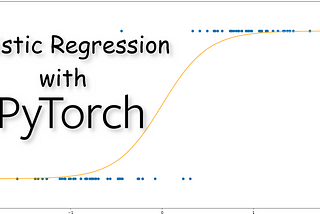
Dorian LazarinNabla SquaredHow to Implement Logistic Regression with PyTorchUnderstand Logistic Regression and sharpen your PyTorch skills·7 min read·Nov 15, 2020----
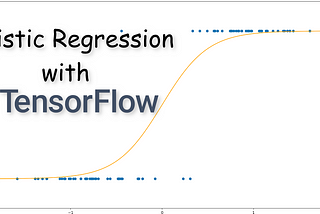
Dorian LazarinNabla SquaredHow to Implement Logistic Regression with TensorFlow…something not as hard as you may think·7 min read·Nov 8, 2020----
Dorian LazarinNabla SquaredAre you tired of scrolling down through logs when training an ML model?Try this Jupyter extension·3 min read·Nov 5, 2020----
Dorian LazarinNabla SquaredThe best 2 books to learn C & C++How I learned more in 3 months rather than 4 years·3 min read·Nov 4, 2020----